
- 멀티쓰레드 프로그래밍 주요 사항
: 올바른 결과가 나와야 함 ( 무한루프에 빠지거나, 프로그램이 오류로 종류되면 안됨 )
: 이를 사용한 성능향상이 커야함 ( 적으면 멀티쓰레드를 쓰는 이유가 없음 )
: 멀쓰 프로그래밍은 하나의 프로그램을 나눠서 작성하는 것
- 위에서 틀린 결과가 나온 이유
: Data Race -> sum += 2
: 공유 메모리를 여러 쓰레드에서 읽고 쓰고, 이 순서에 따라 실행 결과가 예상과는 달라진다
: Data Race ⇒ 복수의 쓰레드가 하나의 메모리에 동시에 접근 & 적어도 한 개의 write
: 읽고 - 더하고 - 쓰는 이 사이에 context switching이 일어나서 문제 (동시 접근 -> read, write)
─ 앞의 프로그램을 싱글 코어에서 동작시키면?
─ 앞의 프로그램을 “sum+=2”로 바꾸면?
─ 앞의 프로그램의 “sum+=2”를 “_asm add sum,2”로 바꾸면?
─ “_asm add sum,2”로 바꾼 후 싱글 코어에서 동작?
4번째의 경우를 제외하고 올바른 값이 나오지 않는다.
→ Data Race를 없애면 된다
→ Lock / Unlock 사용 : 여러 개의 쓰레드가 동시에 접근할 수 없도록 함 (동시에 하나만 접근 하도록 한다)
- Lock과 Unlock
#include <iostream>
#include <thread>
#include <mutex>
int sum;
std::mutex m1;
void thread_work()
{
for (auto i = 0; i < 25000000; ++i) {
m1.lock();
// Critical Section
sum = sum + 2;
m1.unlock();
}
}
int main()
{
std::thread t1{ thread_work };
std::thread t2{ thread_work };
t1.join();
t2.join();
std::cout << "sum = " << sum << std::endl;
}
: Mutex 객체는 전역 변수로 선언하고 같은 객체 사이에서만 Lock과 Unlock이 동작하도록 한다.
: 서로 동시에 실행되어도 괜찮은 critical section이 존재하면 다른 mutex객체로 보호하는 것이 좋다
→ 같은 mutex를 사용하면 동시에 실행이 불가능 함
서로 상호 배제를 해야 하는데 모든 크리티컬 섹션을 다 상호 배제를 해야 하는가?
→ no (성능 저하), 같이 실행 되어도 문제가 없으면 안 해도 됨. 따라서 객체로 선언해서 구현함.
[ Lock()을 사용한 프로그램과 Lock()을 사용하지 않은 프로그램의 속도 비교 ]

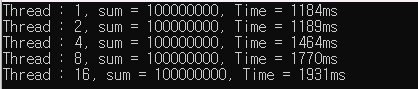
→ 근데 왜 No lock인데 연산 결과가 1억이 나오는가? DataRace로 인해 잘못된 결과 값이 나와야 하는거 아닌가?
→ 현재 Release 모드로 실행 中 → vs 컴파일러 인공지능에 의해 자동 최적화됨 (루프 안돌아가고 단순 레지스터 연산 처리 )
→ 최적화를 하지 않기 위해 변수를 volatile을 사용하여 선언해주면 최적화 되지 않은 값이 나옴
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <vector>
using namespace std;
using namespace std::chrono;
volatile int sum;
mutex a;
// 전역변수를 최대한 만들지마라 -> 함수 매개변수로 넘겨라
void thread_work(const int num_threads)
{
for (auto i = 0; i < 5000'0000 / num_threads; ++i) {
// a.lock();
sum = sum + 2;
// a.unlock();
}
}
int main()
{
/*char ch;
cin >> ch;*/
for (int num_threads = 1; num_threads <= 16; num_threads *= 2) {
sum = 0;
auto start_t = high_resolution_clock::now();
vector<thread> threads;
for (int i = 0; i < num_threads; ++i)
threads.emplace_back(thread_work, num_threads);
for (auto& th : threads)
th.join();
auto exec_t = high_resolution_clock::now() - start_t;
auto ms = duration_cast<milliseconds>(exec_t).count();
std::cout << "Thread : " << num_threads << ", sum = " << sum << ", Time = " << ms << "ms" << endl;
}
}
- Lock() : 한 번에 하나의 쓰레드만을 실행 시키기에 병렬성이 감소함, Lock을 얻지 못하면 Queue에 순서를 저장하고 스핀
- Lock 자체가 오버헤드이기에 심각하게 성능이 저하되는 현상을 볼 수 있음
→ 해결방법은?
→ Lock을 안쓰면 됨. Sum += 2를 할 동안 다른 thread가 실행되지 못하도록 하면 됨
→ atomic : lcok없이 상호배제를 고려해서 굴러감, 함부로 최적화하지 않음, 정해진 순서대로 읽고 씀. atomic 연산끼리도 실행순서 바뀌지 않음 + 근데 다른 연산이랑도 바꾸지 않음

#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <vector>
#include <atomic>
using namespace std;
using namespace std::chrono;
atomic <int> sum = 0;
mutex a;
void thread_work(const int num_threads)
{
for (auto i = 0; i < 5000'0000 / num_threads; ++i) {
// a.lock();
sum = sum + 2;
// a.unlock();
}
}
int main()
{
/*char ch;
cin >> ch;*/
for (int num_threads = 1; num_threads <= 16; num_threads *= 2) {
sum = 0;
auto start_t = high_resolution_clock::now();
vector<thread> threads;
for (int i = 0; i < num_threads; ++i)
threads.emplace_back(thread_work, num_threads);
for (auto& th : threads)
th.join();
auto exec_t = high_resolution_clock::now() - start_t;
auto ms = duration_cast<milliseconds>(exec_t).count();
std::cout << "Thread : " << num_threads << ", sum = " << sum << ", Time = " << ms << "ms" << endl;
}
}
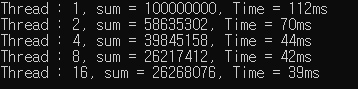
- 문제 발생 ) 생각보다 성능이 극적으로 많이 줄지는 않았고, 값도 엉터리로 나옴.

- sum += 2와 sum = sum + 2는 결과값이 다르다 (위의 사진)
_asm add sum,2
_asm lock add sum, 2;
→ 그럼 어떻게 해?
→ 처음부터 DataRace가 적도록 작성하면 좋다
→ Lock이나 Atomic 연산을 완전히 없애는 것이 가능한가?
→ No.
// Data Race 최소화
void optimal_thread_work(const int num_threads)
{
volatile int local_sum = 0;
for (auto i = 0; i < 5000'0000 / num_threads; ++i)
local_sum += 2;
a.lock();
sum += local_sum;
a.unlock();
}
→ 다른 정답은 있을까?
volatile int sum;
volatile int sum_arr[16 * 16];
mutex a;
void thread_work(const int num_threads, const int th_id)
{
volatile int local_sum = 0;
for (auto i = 0; i < 5000'0000 / num_threads; ++i) {
sum_arr[th_id * 16] = sum_arr[th_id * 16] + 2;
}
}
int main()
{
for (int num_threads = 1; num_threads <= 16; num_threads *= 2) {
sum = 0;
auto start_t = high_resolution_clock::now();
vector<thread> threads;
for (int i = 0; i < num_threads; ++i)
threads.emplace_back(thread_work, num_threads, i);
for (auto& th : threads)
th.join();
auto exec_t = high_resolution_clock::now() - start_t;
auto ms = duration_cast<milliseconds>(exec_t).count();
std::cout << "Thread : " << num_threads << ", sum = " << sum << ", Time = " << ms << "ms" << endl;
}
}
→ Cache Thrashing - Invalidation PingPong 발생할 수도.
→ 원인은 False Sharing이다.

: Cache Thrashing - CPU의 캐시 메모리가 계속 무효화되고 다시 채워지는 현상
: Invalidation PingPong - 두 개 이상의 코어가 동일한 데이터에 동시에 접근하여 그 데이터의 캐시 라인을 번갈아 무효함
: False Sharing - 두 개 이상의 코어가 동시에 접근하는 메모리 영역이 같은 캐시라인에 위치해 발생함. 공유되지 않은 메모리에 대한 문제.
관련 글은 이 글을 참고하자 → https://hwan-shell.tistory.com/230
C++ false sharing이란?(거짓 공유)
1. false sharing 이란?? false sharing은 멀티 쓰레드 환경 + CPU의 멀티 코어에서 발생됩니다. cpu 내부의 코어와 코어간의 메모리 정보가 공유되어 하드웨어 적으로 병목현상이 일어나는 것을 뜻합니다.
hwan-shell.tistory.com
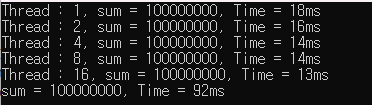
→ Cache Thrashing 해결
: 쓰레드 마다 서로 다른 캐시 라인을 사용하도록 한다. alignas 키워드 사용 or 패딩(padding)
volatile int sum = 0;
struct NUM {
alignas(64) volatile int sum;
};
NUM sum_arr[16];
mutex a;
void thread_work(const int num_threads, const int th_id)
{
for (auto i = 0; i < 5000'0000 / num_threads; ++i) {
sum_arr[th_id].sum = sum_arr[th_id].sum + 2;
}
}
int main()
{
for (int num_threads = 1; num_threads <= 16; num_threads *= 2) {
sum = 0;
for (auto& s : sum_arr) s.sum = 0;
auto start_t = high_resolution_clock::now();
vector<thread> threads;
for (int i = 0; i < num_threads; ++i)
threads.emplace_back(thread_work, num_threads, i);
for (auto& th : threads)
th.join();
for (int i = 0; i < num_threads; ++i)
sum = sum + sum_arr[i].sum;
auto exec_t = high_resolution_clock::now() - start_t;
auto ms = duration_cast<milliseconds>(exec_t).count();
std::cout << "Thread : " << num_threads << ", sum = " << sum << ", Time = " << ms << "ms" << endl;
}
sum = 0;
auto start_t2 = high_resolution_clock::now();
for (int i = 0; i < 5000'0000; ++i)
sum = sum + 2;
auto exec_t2 = high_resolution_clock::now() - start_t2;
auto ms2 = duration_cast<milliseconds>(exec_t2).count();
std::cout << "sum = " << sum << ", Time = " << ms2 << "ms" << endl;
}
< 이것은 꼭 알자 >
- 병렬 컴퓨팅이란 무엇인가?
- 쓰레드란 무엇인가?
- 왜 멀티쓰레드 프로그래밍을 해야 하는가?
- 멀티쓰레드 프로그래밍은 어떻게 하는가?
- 멀티쓰레드 프로그래밍의 어려움
- Data Race
- 성능
- 멀티쓰레드 프로그래밍의 종류
1) Heterogeneous 멀티쓰레딩
: 쓰레드 마다 맡은 역할이 다름
: 다른 코드 파트를 실행하기 때문에 쓰레드 간의 Load Balancing(부하 분산) 힘듦
: 병렬성이 제한됨
2) Homogeneous 멀티쓰레딩
: Data/Event Driven 프로그래밍
: 모든 쓰레드는 Symmetric(대칭적)함 → 동일한 역할을 수행
: 자동적인 Load Balancing
: 병렬성 제한 없음
: 작업 분배 Queue를 비롯한 일반적 병렬 자료구조 필요
- 게임 서버 (MMORPG)
: Window 멀티쓰레드 + Network I/O API인 IOCP
: 일반적 Select()으로는 몇 천개의 Socket 을 관리할 수 없으며 소켓 하나당 하나의 쓰레드는 OS의 과부하
: Homogeneous 멀티쓰레딩 → Worker thread의 pool 사용(HW Core 개수의 1.5배, 네트워크 데이터 처리와 AI루틴)
: 소켓을 통해 패킷이 올 때 마다, OS가 thread pool의 쓰레드를 하나 깨워서 패킷의 처리를 맡김.
: DataBase Query - 쓰레드의 blocking을 초래하기에 blocking 전용 쓰레드를 따로 둬 작업
: NPC AI - 보통 NPC는 너무 많이 존재함, Timer 쓰레드를 사용해 활성화한 NPC의 이벤트만을 처리한다
: 평상시에 CPU 낭비는 괜찮다. 최대 동접이 중요
'🧐 Study > MultiThread' 카테고리의 다른 글
| [05주차] 동기화 연산 & CAS (0) | 2024.04.24 |
|---|---|
| [04주차] 메모리 일관성 (0) | 2024.04.18 |
| [03주차] 멀티쓰레드 프로그래밍 주의사항 & 상호배제 알고리즘 (1) | 2024.04.18 |
| [01주차B] 멀티코어 HW & 멀티쓰레드프로그래밍 시작 (0) | 2024.03.28 |
| [01주차A] 멀티쓰레드 프로그래밍 소개 (0) | 2024.03.12 |